When people say they're "writing kernels" or "optimizing GPU code," what are they actually doing? This post explains the core concepts and what the work actually involves.
The short version
A GPU kernel is a function designed to run in parallel on a GPU instead of a CPU. Writing one means figuring out how to split a computation across thousands of parallel threads and how to move data efficiently through the GPU's memory hierarchy.
Most ML code never touches kernels directly. When you call torch.softmax() or jax.nn.softmax(), you're running a kernel someone else wrote. Kernel authors are the people who wrote that underlying implementation, or who write custom versions when the built-in one isn't fast enough.
Why GPUs need special code
CPUs and GPUs have fundamentally different designs:
- A CPU has a few powerful cores optimized for low latency—finishing individual tasks quickly. It runs one (or a handful of) threads fast.
- A GPU has thousands of smaller cores optimized for high throughput—finishing many tasks at once. Individual threads are slower, but the aggregate work completed per second is much higher.
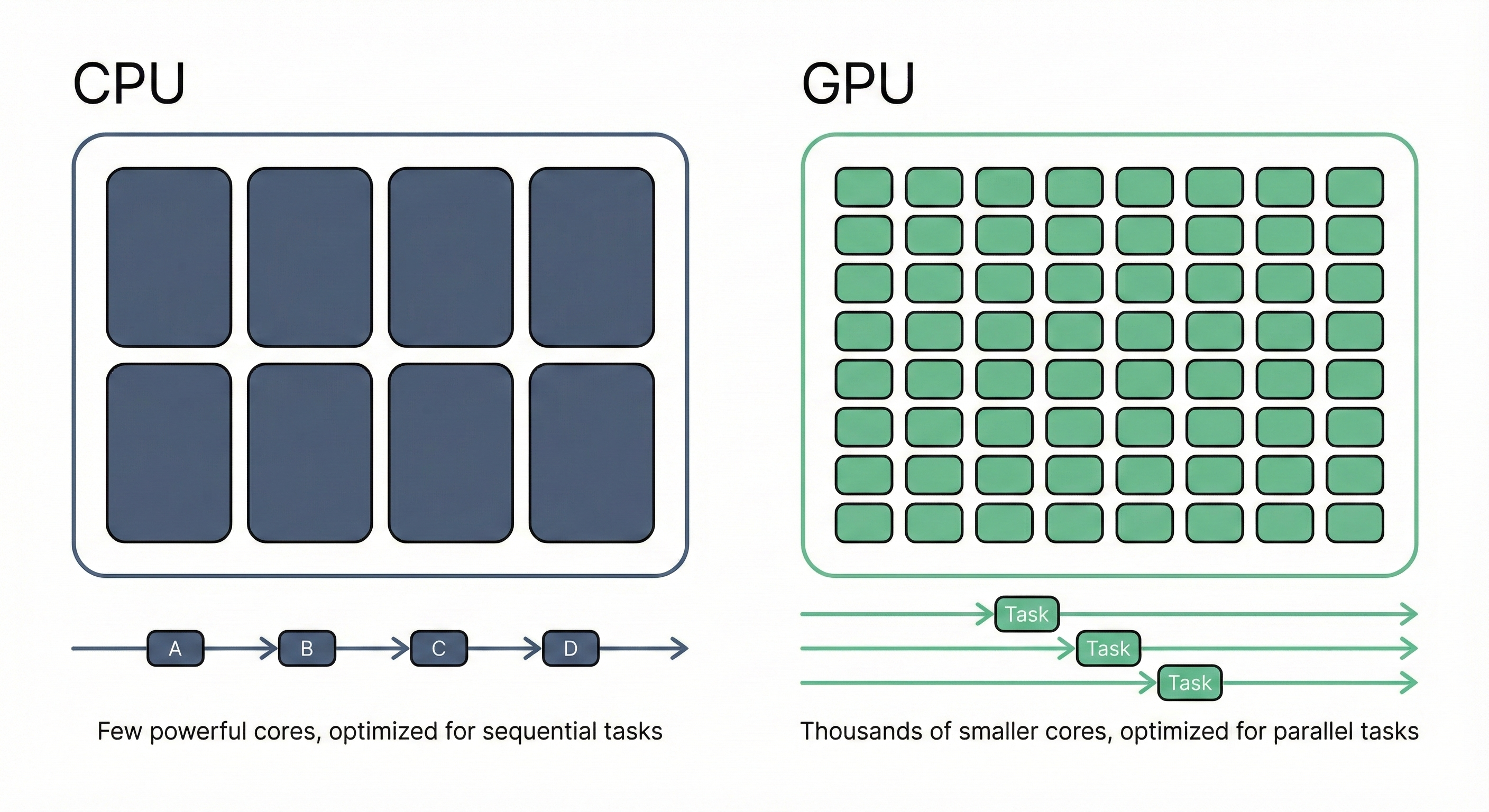
This means you can't take CPU code and run it on a GPU. You need to restructure the computation to express parallelism explicitly: which thread handles which data, how threads coordinate, and how data moves between memory levels.
That restructuring is what kernel development is.
The core challenge: memory, not math
The hard part of GPU programming isn't making the math go fast. GPUs are exceptional at arithmetic. A modern GPU can perform tens of trillions of floating-point operations per second.
The hard part is feeding data to the GPU fast enough.
GPU memory bandwidth—the rate at which data moves between memory and the processors—is measured in hundreds of gigabytes per second. That sounds fast, but the GPU can compute far faster than it can read and write data. For many operations, the GPU spends more time waiting for data than doing actual math.
Kernel optimization therefore focuses heavily on memory access patterns and data reuse. The goal is to load data once, do as much computation as possible while it's in fast memory, and avoid unnecessary reads and writes.
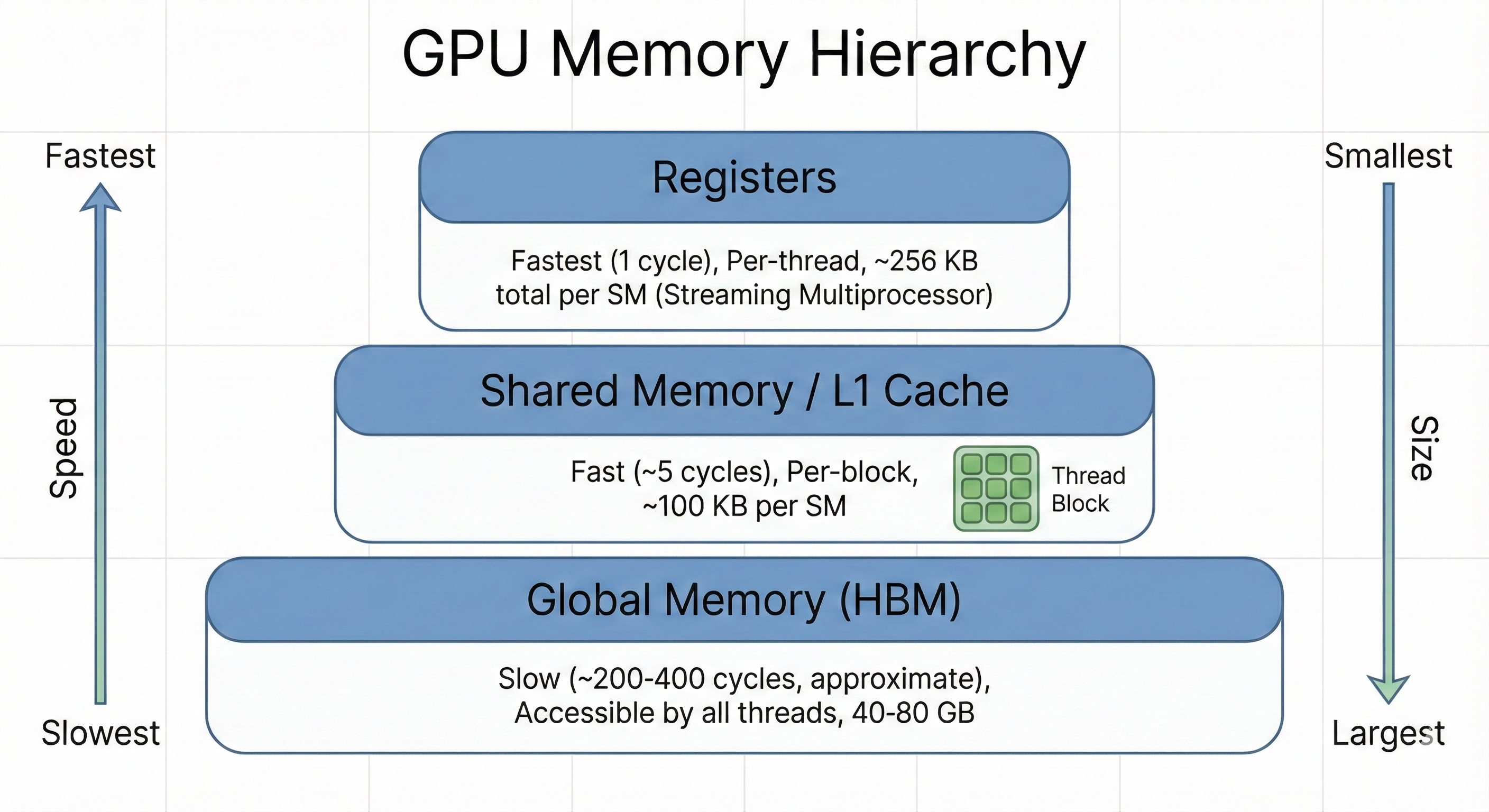
GPUs have a memory hierarchy separate from your system's main RAM. Global memory (High Bandwidth Memory, or HBM) is the GPU's main memory—large but slow (hundreds of cycles of latency, though the GPU hides this by running many threads concurrently). Shared memory is smaller but fast (a few cycles), and sits on-chip. Registers are fastest but limited to individual threads. Good kernels exploit this hierarchy—loading data from global memory into shared memory or registers, operating on it, then writing back.
A concrete example: softmax
To make this concrete, consider softmax, the function that converts a vector of numbers into a probability distribution:
The algorithm has four steps:
- Find the maximum value in the row.
- Subtract the max from each element, then exponentiate.
- Sum the exponentials.
- Divide each element by the sum.
A naive GPU implementation runs four separate kernels, one per step. Each kernel reads the entire row from memory, does a small computation, and writes results back. That's four reads and four writes for the same data, with minimal arithmetic in between.
Because memory bandwidth is the bottleneck, this is wasteful. The GPU spends most of its time moving data, not computing.
A hand-written kernel fuses all four steps into a single pass. It loads each row once, computes the max, the exponentials, the sum, and the final result—all while the data is in fast memory—then writes once. This can be 2–4x faster than the naive version, not because the math is faster, but because the memory traffic is lower.
This ratio of computation to memory traffic is called arithmetic intensity: FLOPs per byte moved. The fused kernel has higher arithmetic intensity, meaning more math per byte. For memory-bound operations like softmax, increasing arithmetic intensity is the primary optimization lever.
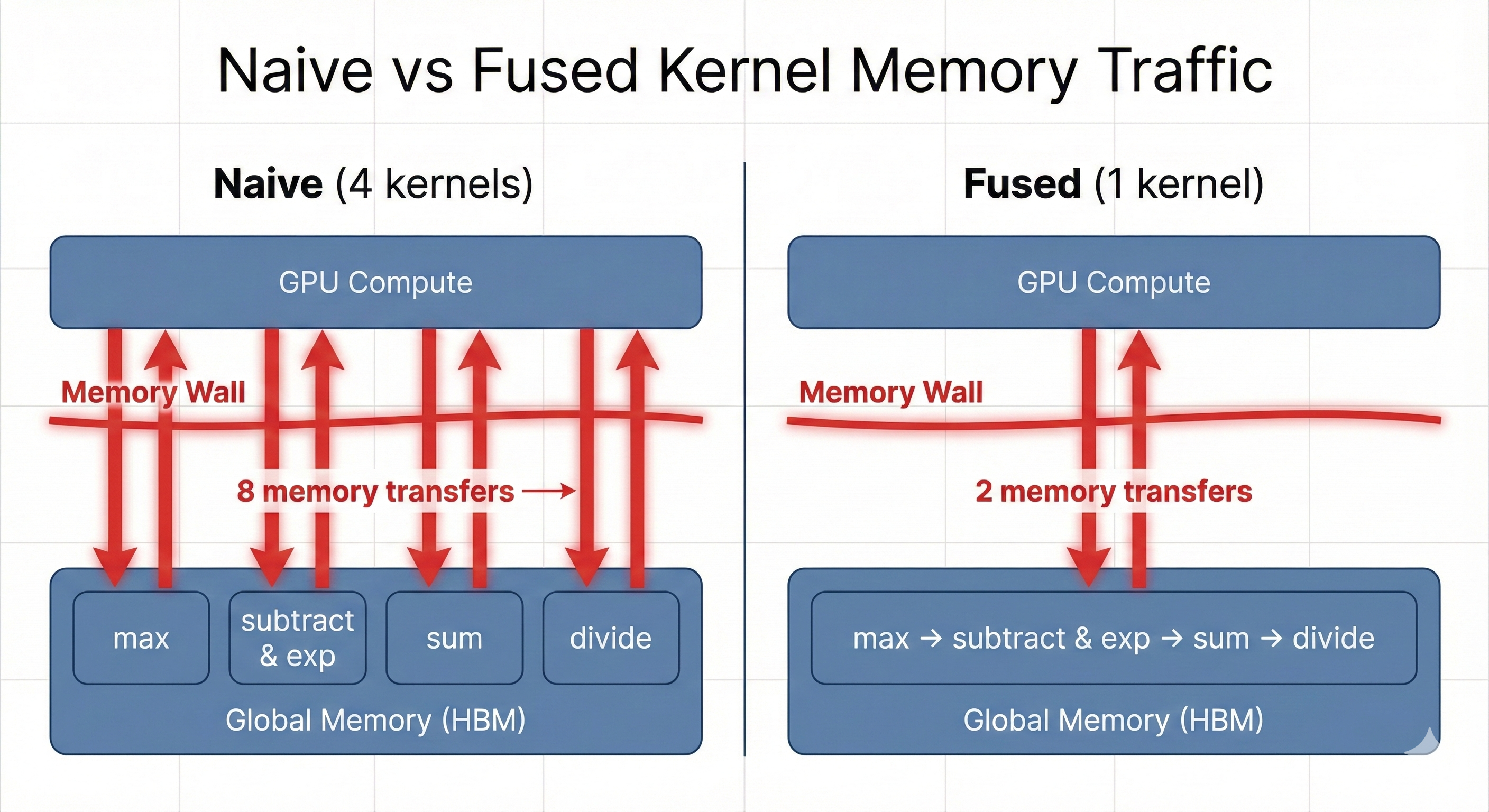
This is what kernel optimization usually looks like: reorganizing computation to minimize data movement.
The mental model: how parallelism works
Before looking at code, here's how GPUs organize parallel work.
Threads are the basic unit of execution. Each thread runs the same code but operates on different data. A softmax kernel might launch one thread per element, or a group of threads per row.
Warps are groups of 32 threads that the GPU schedules together. This is a hardware detail, but it matters: when threads in a warp access memory, the hardware can combine their requests into a single transaction, but only if they're accessing contiguous addresses. This is called coalesced access. Scattered accesses become multiple slower transactions.
Warps are also the unit of scheduling: when one warp is waiting on memory, the GPU switches to another warp to hide latency. If threads within a warp take different branches (e.g., some go into an if, others into else), performance can degrade—GPUs are most efficient when all threads in a warp follow the same path.
Thread blocks (or just "blocks") are groups of threads that can cooperate. Threads in the same block can share fast memory and synchronize with each other. Threads in different blocks cannot. A block contains multiple warps (e.g., a block of 256 threads = 8 warps).
Grids are collections of blocks. When you launch a kernel, you specify a grid size (how many blocks) and a block size (how many threads per block).
For our softmax example, a common approach is one block per row. Within each block, threads cooperate to find the max and sum (these require communication between threads), then each thread computes one element of the output.
Reductions are operations where threads need to combine their results, like finding the max or computing a sum. These require careful coordination: each thread computes a partial result, then threads combine their results in a tree-like pattern until one thread has the final answer.
Writing a kernel in CUDA
CUDA is NVIDIA's low-level programming model. You write C++ code that explicitly manages threads, memory, and synchronization.
In CUDA, you write a single function that every thread executes. Each thread figures out which piece of data it's responsible for by looking up its block index (blockIdx) and thread index within that block (threadIdx). For softmax, we launch one block per row, so block 0 handles row 0, block 1 handles row 1, and so on. Within each block, the threads divide up the elements of that row and cooperate to compute the max, the sum, and the final result.
Here's a CUDA implementation:
__global__ void softmax_kernel(float* input, float* output, int row_size) {
// Shared memory for threads in this block to communicate (size specified at kernel launch)
extern __shared__ float shared[];
// Identify which row this block handles and which thread this is within the block
int row = blockIdx.x;
int tid = threadIdx.x;
// Pointers to this row's input and output
float* row_in = input + row * row_size;
float* row_out = output + row * row_size;
// Step 1: Find the max of this thread's assigned elements
float local_max = -INFINITY;
for (int i = tid; i < row_size; i += blockDim.x) {
local_max = fmaxf(local_max, row_in[i]);
}
// Store this thread's local max in shared memory
shared[tid] = local_max;
__syncthreads(); // Wait for all threads to finish
// Parallel reduction to find the max (search "CUDA parallel reduction" for details)
// Assumes blockDim.x is a power of 2
for (int stride = blockDim.x / 2; stride > 0; stride >>= 1) {
if (tid < stride) {
shared[tid] = fmaxf(shared[tid], shared[tid + stride]);
}
__syncthreads(); // Wait before next iteration
}
float row_max = shared[0]; // All threads can now read the row's max
// Step 2: Compute exp(x - max) for this thread's elements, store them, and sum
float local_sum = 0.0f;
for (int i = tid; i < row_size; i += blockDim.x) {
float exp_val = expf(row_in[i] - row_max);
row_out[i] = exp_val; // Store exponentials in output (will divide in place later)
local_sum += exp_val;
}
// Another parallel reduction to get the total sum
shared[tid] = local_sum;
__syncthreads();
for (int stride = blockDim.x / 2; stride > 0; stride >>= 1) {
if (tid < stride) {
shared[tid] += shared[tid + stride];
}
__syncthreads();
}
float sum = shared[0]; // All threads can now read the total sum
// Step 3: Normalize the stored exponentials in place
for (int i = tid; i < row_size; i += blockDim.x) {
row_out[i] /= sum;
}
}This code shows the concepts from the previous section:
- One block per row:
blockIdx.xidentifies which row this block handles. - Threads cooperate within a block: Each thread processes elements strided by
blockDim.x, then they combine results. - Shared memory for communication:
__shared__declares fast, on-chip memory accessible to all threads in the block. - Explicit synchronization:
__syncthreads()ensures all threads reach the same point before continuing. - Parallel reduction: The stride-halving loop is the tree-like pattern for combining values. Each iteration halves the number of active threads.
To launch this kernel, host code specifies the grid and block dimensions:
// Launch one block per row, 256 threads per block, with shared memory
softmax_kernel<<<num_rows, 256, 256 * sizeof(float)>>>(input, output, row_size);The <<<num_rows, 256, ...>>> syntax is CUDA's way of specifying parallelism: how many blocks, how many threads per block, and how much shared memory to allocate.
A higher-level alternative: Triton
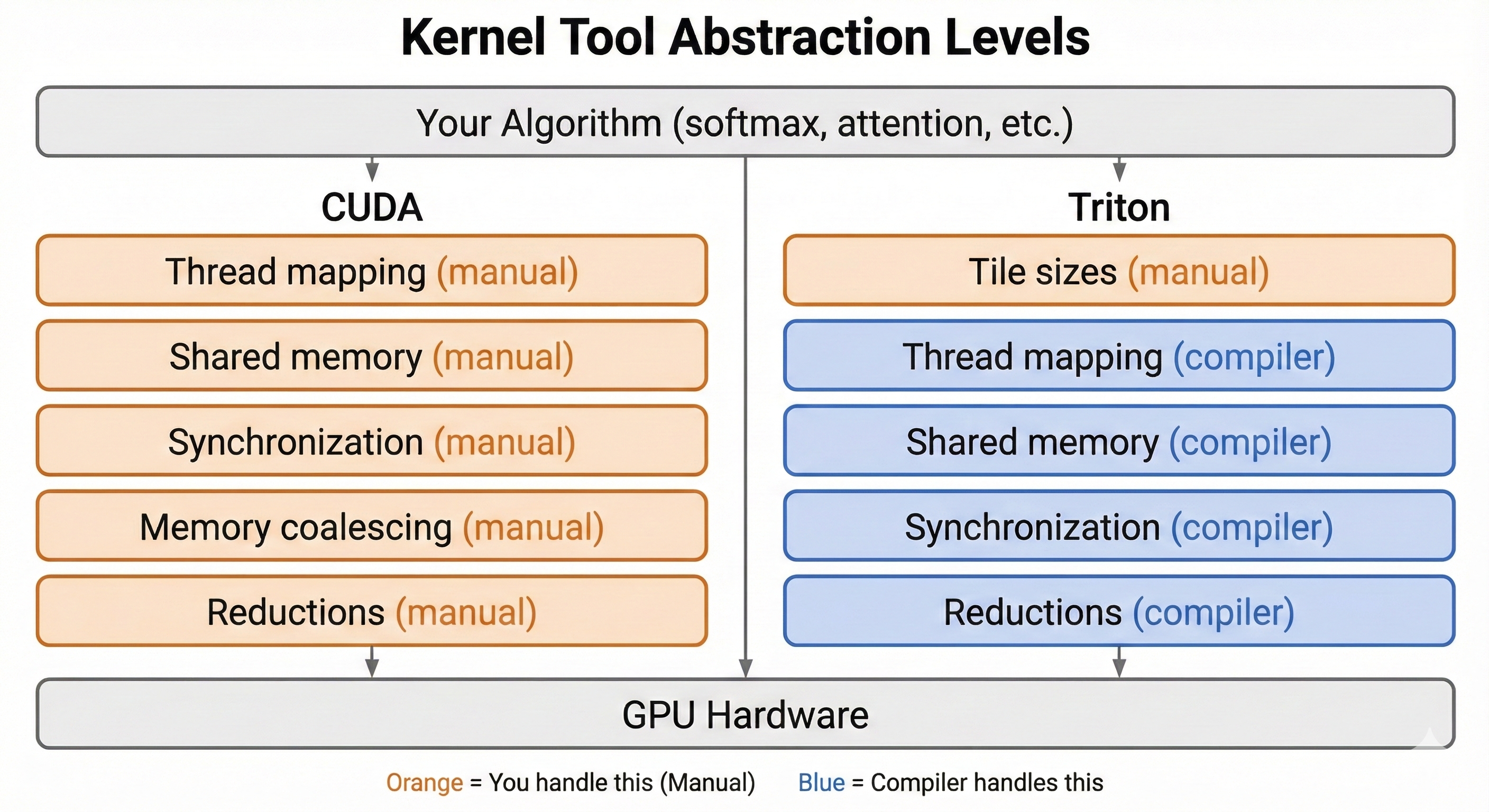
The CUDA implementation above is about 45 lines for a relatively simple operation, and this is a clean version. Production CUDA often includes additional optimizations for warp-level primitives, memory padding to avoid bank conflicts (when multiple threads access the same memory bank simultaneously), and tuning for specific GPU architectures.
Writing efficient CUDA requires deep understanding of GPU architecture. You're reasoning about hardware behavior at a fine granularity: how warps execute, how memory transactions coalesce, how occupancy affects latency hiding. This is learnable, but it's a significant investment.
Triton offers a more accessible path. Developed by OpenAI, Triton lets you write kernels in Python and think in terms of tiles of data rather than individual threads. The compiler handles thread mapping, shared memory management, and synchronization. Unlike CUDA, which only runs on NVIDIA hardware, Triton also has experimental support for AMD GPUs.
Here's the same softmax:
import triton
import triton.language as tl
@triton.jit
def softmax_kernel(input_ptr, output_ptr, row_size, BLOCK_SIZE: tl.constexpr):
# Assumes row_size <= BLOCK_SIZE (single tile per row)
row_idx = tl.program_id(0)
row_start = row_idx * row_size
offsets = tl.arange(0, BLOCK_SIZE)
mask = offsets < row_size
# Load the row
row = tl.load(input_ptr + row_start + offsets, mask=mask, other=-float('inf'))
# Compute softmax
row_max = tl.max(row, axis=0)
numerator = tl.exp(row - row_max)
denominator = tl.sum(numerator, axis=0)
result = numerator / denominator
tl.store(output_ptr + row_start + offsets, result, mask=mask)Same algorithm, 15 lines instead of 45. The reductions (tl.max, tl.sum) are built-in. No manual synchronization. No shared memory declarations. The compiler generates the thread mapping and memory management that you'd write by hand in CUDA.
The mask parameter handles edge cases: if BLOCK_SIZE is 256 but row_size is 200, the mask prevents reading or writing out-of-bounds elements. The other=-float('inf') specifies what value to use for masked-out elements during the load. Using negative infinity ensures they don't affect the max calculation.
The BLOCK_SIZE: tl.constexpr parameter tells the Triton compiler to generate a specialized kernel for that specific block size, enabling optimizations like loop unrolling that wouldn't be possible with a runtime value.
The tradeoff is control. You can't hand-tune warp-level details or manually optimize shared memory layout. But for many use cases, Triton's compiler generates code within 80-90% of hand-optimized CUDA, with significantly less development time.
The optimization workflow
Writing a correct kernel is straightforward. Getting it to run fast takes longer.
A typical workflow:
- Write a correct implementation. Get the right answer first.
- Profile. Tools like NVIDIA Nsight Compute show where time goes: memory stalls, low occupancy, uncoalesced access.
- Identify the bottleneck. Is it memory bandwidth? Compute? Synchronization overhead?
- Change one thing. Adjust tile sizes, memory access patterns, or the parallelization strategy.
- Reprofile. Verify the change helped (it often doesn't, or helps one metric while hurting another).
- Repeat.
This cycle can take days or weeks for complex kernels.
Common optimizations include:
- Fusing operations: Combining multiple framework calls into a single kernel to reduce memory traffic.
- Tuning tile sizes: Adjusting block dimensions to balance parallelism with memory usage for specific hardware.
- Improving memory access patterns: Reorganizing data or access order so threads read contiguous addresses.
- Reducing synchronization: Restructuring algorithms to minimize points where threads wait for each other.
- Managing occupancy: Adjusting resource usage per thread to allow more concurrent warps (as discussed earlier, more warps means better latency hiding).
These optimizations are hardware-specific. A kernel tuned for an A100 might perform differently on an H100.
Who writes kernels?
Most ML practitioners never write kernels. Framework operations cover standard use cases, and libraries like cuDNN and cuBLAS provide highly optimized implementations of common operations.
People who write kernels typically fall into a few categories:
- ML framework developers: Building PyTorch, JAX, or TensorFlow operations.
- ML researchers: Implementing new operations that don't exist in frameworks, like novel attention mechanisms.
- ML infrastructure engineers: Optimizing inference for production deployment where performance directly affects cost.
- Hardware vendors: Writing optimized libraries for their chips.
If you're doing ML research or applications, you can go far without writing kernels. If you're working on ML systems or infrastructure, understanding this domain becomes more relevant.
A note on simplifications
This post simplifies certain details to focus on core concepts:
- The code examples are pedagogical, not production-ready. Production kernels handle edge cases (non-power-of-2 sizes, large rows requiring multiple tiles), use warp-level primitives for faster reductions, and are tuned for specific architectures.
- GPU architecture is more complex than "thousands of small cores"—modern GPUs have streaming multiprocessors (SMs), different types of cores (CUDA cores, tensor cores), and varying capabilities by generation.
- Memory latency numbers (cycles to access registers vs shared memory vs global memory) are approximate and vary across GPU architectures.
- Not all operations are memory-bound. Dense matrix multiplications on modern GPUs with tensor cores can be compute-bound.
- The "80-90% of CUDA performance" claim for Triton varies significantly by workload.
For production work, profiling on your specific hardware with your specific workloads is essential.
Further reading
- Triton tutorials: Hands-on introduction, including a softmax example.
- CUDA C++ Programming Guide: Comprehensive CUDA reference.
- FlashAttention paper: A case study in aggressive kernel optimization.